
접근에 따라 S3의 객체를 다르게 제공하는 S3 Object Lambda 액세스 포인트에 대해

안녕하세요 클래스메소드의 이수재입니다.
S3의 객체를 이용할 때 액세스 경로에 따라서 반환하는 객체를 조정할 수 있는 기능인 S3 Object Lambda 라는 기능이 있습니다.
해당 기능이 어떤 기능인지 그리고 어떻게 사용하는지 알아보겠습니다.
S3 Object Lambda 란
검색된 데이터를 애플리케이션에 반환하기 전에 자체 코드를 추가하여 처리 할 수 있는 새로운 기능입니다. S3 Object Lambda는 기존 애플리케이션과 함께 작동하며, AWS Lambda 함수를 사용하여 S3에서 검색되는 데이터를 자동으로 처리하고 변환합니다.
간단히 말하자면 S3에서 객체를 가져오기 전에 전에 Lambda에서 전처리를 하고 특정 액세스 포인트를 통하여 해당 결과를 받아오는 기능입니다.
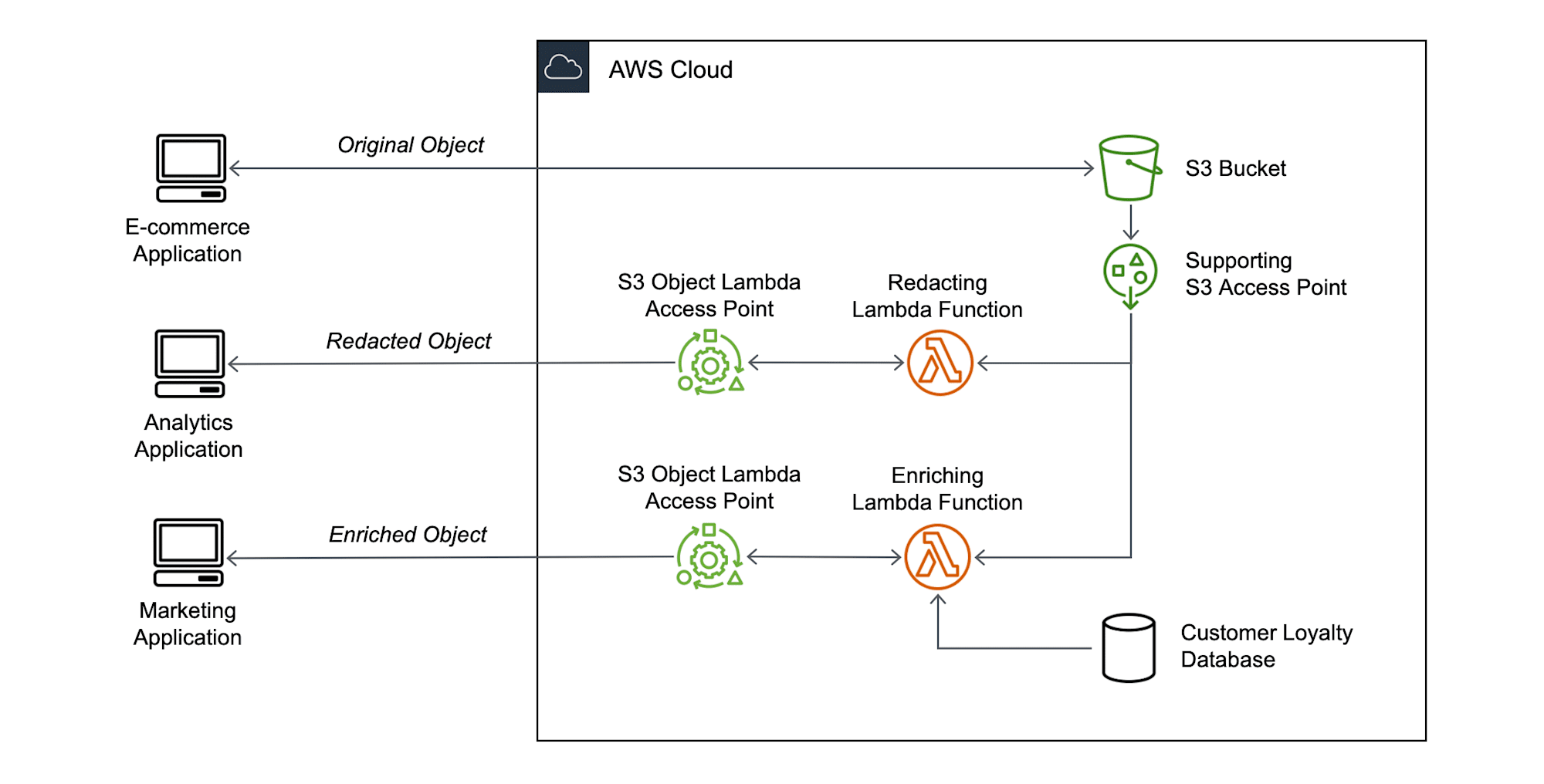
출처 : AWS 공식 문서
언제 사용하는가
원본의 객체를 그대로 어플리케이션에 전달하면 안되는 경우에 사용하는 경우가 많습니다.
예로 들면 객체에 기밀성어 높은 내용이 기록된 오브젝트가 여러 어플리케이션에서 필요한 경우, 각 어플리케이션에 맞춰서 필요한 정보만을 제공하도록 람다가 전처리를 하고 처리가 된 객체를 어플리케이션이 처리하도록 설계할 수 있습니다.
공식 문서에 따르면 다음과 같은 상황이 예로 적혀있습니다.
- 분석 또는 비 생산 환경을 위해 개인 식별 정보 수정
- XML을 JSON으로 변환하는 것과 같은 데이터 형식 간 변환
- 다른 서비스 또는 데이터베이스의 정보로 데이터 보강
- 다운로드 되는 파일 압축 또는 압축 해제
- 개체를 요청한 사용자와 같은 발신자 별 세부 정보를 사용하여 즉시 이미지 크기 조정 및 워터 마킹
- 데이터에 액세스하기 위한 사용자 지정 권한 부여 규칙 구현
설정 방법
구축은 다음과 같은 흐름으로 진행됩니다.
- 전처리용 람다 생성
- S3 객체 람다 액세스 포인트 작성
- 액세스 포인트에 권한 부여
- 어플리케이션에서 연결
전제 조건
어플리케이션에서 가지고 와야하는 원본 json은 다음 데이터를 가지고 있습니다
{
"secretA": "aaa",
"secretB": "bbb",
"plainText": "abcd"
}
PlaninText 는 기본적으로 확인할 수 있지만 액세스 포인트에 따라서 secretA 는 확인할 수 없도록 키를 삭제합니다.
전처리 람다 생성
S3 Object Lambda 액세스 포인트를 통해 json을 열고 특정 데이터를 지우는 함수를 생성합니다.
함수는 S3에 직접 연결하는 것이 아닌 S3 Object Lambda를 거쳐서 데이터를 가져옵니다.
따라서 코드를 작성하기 전 S3 Object Lambda의 이벤트 구문을 알아 둘 필요가 있습니다.
{
"xAmzRequestId": "1a5ed718-5f53-471d-b6fe-5cf62d88d02a",
"getObjectContext": {
"inputS3Url": "https://your-bucket-name.s3-accesspoint.us-east-1.amazonaws.com/s3.txt?X-Amz-Security-Token=...",
"outputRoute": "io-iad-cell001",
"outputToken": "..."
},
"configuration": {...
},
"userRequest": {...
}
},
"userIdentity": {...
},
"protocolVersion": "1.00"
}
S3 Object Lambdad에서 객체를 읽어오기에 필요한 정보는 getObjectContest 에 있습니다.
inputS3Url은 미리 서명된 url 입니다. 함수는 이 url로 객체를 요청합니다.
미리 서명된 url을 사용하기에 함수에는 S3를 조작하기 위한 권한 부여가 불필요합니다.
outputRoute 및 outputToken 매개 변수는 WriteGetObjectResponseAPI 를 사용하여 수정 된 객체를 다시 보내는 데 필요한 매개 변수입니다.
함수에 연결된 IAM 역할의 권한에 WriteGetObjectResponse 권한을 추가합니다.
객체를 읽어오고 수정하는 코드는 다음과 같습니다.
import json
import boto3
import requests
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
object_get_context = event["getObjectContext"]
s3_url = object_get_context["inputS3Url"]
request_route = object_get_context["outputRoute"]
request_token = object_get_context["outputToken"]
r = requests.get(s3_url)
original_object = r.content.decode('utf-8')
json_data = json.loads(original_object)
del(json_data['secretA'])
json_body = json.dumps(json_data, indent=4).encode('utf-8')
s3.write_get_object_response(
Body=json_body,
RequestRoute=request_route,
RequestToken=request_token)
return {'status_code': 200}
액세스 포인트 만들기
우선 S3의 액세스 포인트을 생성합니다.
해당 S3 버킷의 콘솔에서 생성할 수 있습니다.
필요에 따라 액세스 포인트 정책을 수정합니다.
- 참고: 공식 문서
그럼 다음과 같이 액세스 포인트가 생성됩니다.
이어서 S3 객체 람다 액세스 포인트을 생성합니다.
콘솔 기준으로 사이드바 메뉴에 객체 람다 액세스 포인트 메뉴가 있습니다.
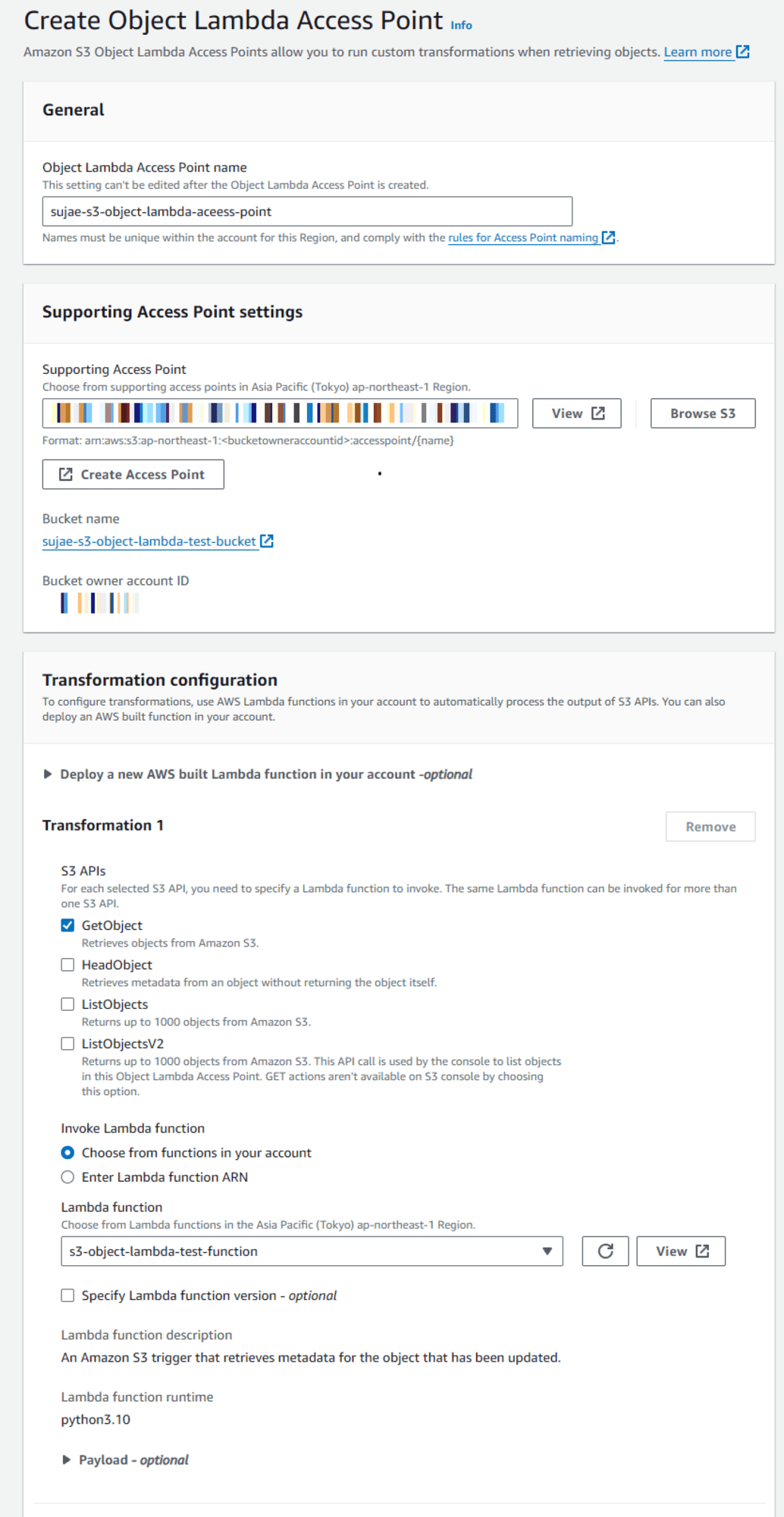
S3 객체 람다 액세스 포인트의 이름을 정해준 후 방금 생성한 S3 액세스 포인트를 지정해줍니다.
변환(Transformation)에서는 해당 액세스 포인트에 대한 어떤 요청에 대해 람다가 처리할 것인지를 선택합니다.
이번 글에서는 객체를 받아오는 getobject에 대해 해당 람다가 실행되도록 설정하였습니다.
로깅이 필요하다면 Request metrics 을 활성화 합니다.
데이터 확인
오리진 버킷(sujae-s3-object-lambda-test-bucket)에 파일을 업로드 한 후 액세스 포인트의 ARN으로 파일을 요청하는 코드를 실행해보면 파일이 변환된 것을 확인할 수 있습니다.
import boto3
from botocore.config import Config
s3 = boto3.client('s3')
def lambda_handler(event, context):
# TODO implement
object = s3.get_object(Bucket = event["url"], Key = event["key"])
print("test")
print(object['Body'].read().decode('utf-8'))

비용
S3 객체 람다 액세스 포인트를 이용하면 반환된 객체의 크기 당 비용이 발생합니다.
2024년 8월 22일 서울 리전 기준으로 GB당 0.005 USD 가 청구됩니다.
또한 람다 함수를 실행하는 비용도 별도로 발생하게 됩니다.
비용의 예는 공식 문서를 참조해주세요.
- S3 비용
- 변환 및 쿼리 탭을 확인해주세요.
마무리
만약 다른 어플리케이션에서 접근할 때 파일의 다른 항목을 확인하지 못하게 하고 싶은 경우, 또 다른 액세스 포인트와 람다를 추가하고 위와 같이 설정하면 됩니다.
긴 글 읽어주셔서 감사합니다.
오탈자 및 내용 피드백은 must01940 지메일로 보내주시면 감사합니다.
